Go并发
1.传统线程模型存在的问题
传统线程模型存在的局限性:
线程是操作系统调度的最小单位,每个线程都需要独立的栈空间,通常在 1-8MB 之间。当你创建大量线程时,仅仅是内存开销就足以让系统崩溃。更严重的是,线程间的上下文切换成本极高,因为需要保存和恢复大量的 CPU 寄存器状态,这个过程可能需要几千个 CPU 周期。
例子:
想象一下你是一家餐厅的老板,每当有客人来用餐时,你就雇佣一名专门的服务员来服务这位客人。这看起来很合理,每个客人都能得到专属服务。但问题来了:如果同时来了一万个客人,你就需要雇佣一万名服务员(线程)。每个服务员不仅需要工资(内存),还需要独立的工作空间(栈空间),更要命的是,当服务员们需要协调工作时(上下文切换),整个餐厅的效率就会急剧下降。
2.协程的出现
协程介绍:
- 本质是用户态的轻量级线程,它们运行在用户空间,不需要操作系统内核的参与
- 协程的切换完全由程序控制,切换成本极低,通常只需要几个 CPU 周期
- 协程的栈空间可以动态增长,初始化时可能只有几 KB ,需要时才会扩展
协程解决传统线程模型的问题:
创建成千上万个协程而不用担心资源消耗,每个协程都可以专注于处理一个独立的任务,而协程间的切换几乎没有性能损耗
3.Go 的 Goroutine
Goroutine,Go语言中的一种轻量级线程,用于并发编程
一个 goroutine 的初始栈大小只有 2KB,相比传统线程的 MB 级别栈空间,这简直是质的飞跃。当栈空间不够时,Go 运行时会自动进行栈扩容,这个过程对程序员来说是完全透明的。
Goroutine 语法:使用 go 关键字开启一个协程
go func(){
// to do
}例子,使用 协程 以一个不同的、新创建的 协程 来执行一个函数
package main
import (
"fmt"
"time"
)
func sayHello() {
for i := 0; i < 5; i++ {
fmt.Println("Hello")
time.Sleep(100 * time.Millisecond)
}
}
func main() {
go sayHello() // 启动 Goroutine
for i := 0; i < 5; i++ {
fmt.Println("Main")
time.Sleep(100 * time.Millisecond)
}
}执行结果:
Main
Hello
Main
Hello
...goroutine 存在的问题:
我们可以在一个程序中使用 go 关键字轻松启动数万个这样的 goroutine,而系统依然能够流畅运行
问题:如果我们能够创建数万个 goroutine,但操作系统只给我们几个或几十个线程,那么这些 goroutine 是如何在有限的线程上运行的呢?
解决: Go 运行时调度器的核心挑战,也是 GMP 模型要解决的根本问题
4.被废弃的 G-M 模型
为了实现我们创建的 goroutine 协程在线程上执行,系统采用了 M:N 的模式,即 M 个操作系统线程(Machine)去执行 N 个 goroutine(Goroutine)。这个模式的核心在于调度器,它负责将 goroutine 分配给操作系统线程。
这时候需要一个调度器来管理 goroutine 和操作系统线程之间的映射关系。
久远时期采用的是 G-M 模型,G 代表 Goroutine,M 代表 Machine(操作系统线程)。所有的 Goroutine 被放在一个全局队列中,所有的 M 都从这个全局队列中获取 Goroutine 来执行。
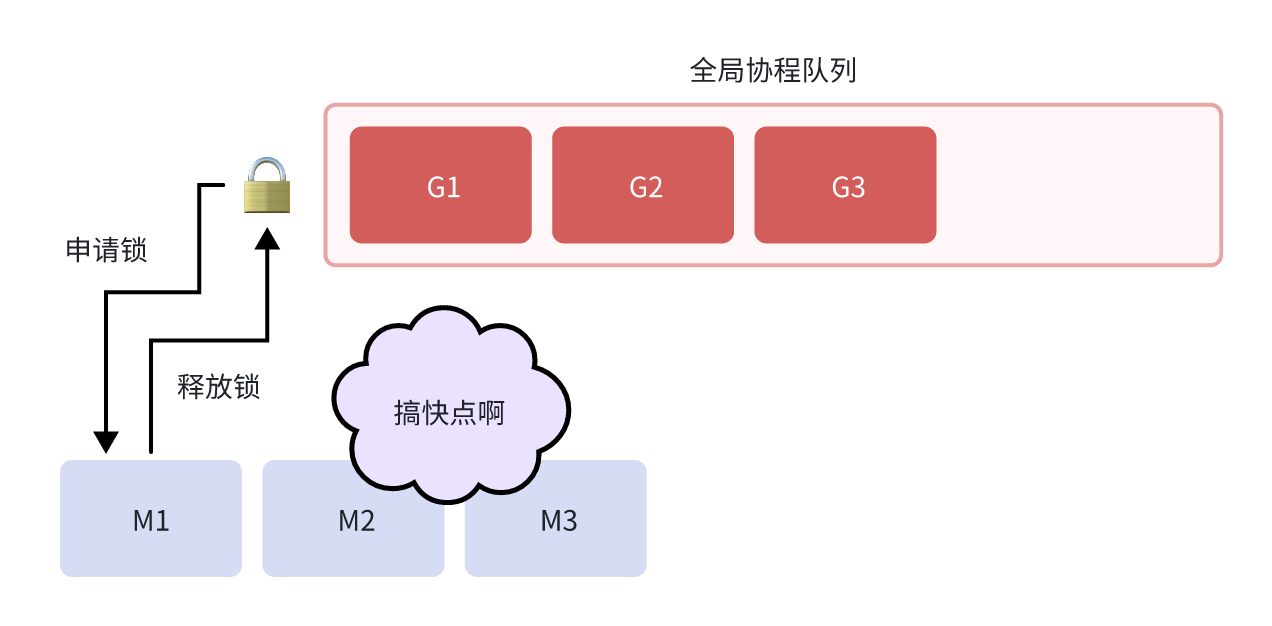
类比:一个工厂的生产线:所有的任务(Goroutine)都放在一个传送带(全局队列)上,所有的工人(M)都从传送带上取任务来完成
但是,这个简单的设计存在致命的性能问题:
- 全局锁竞争:所有的 M 都需要从同一个全局队列中获取 Goroutine,这意味着每次获取都需要加锁。在高并发场景下,大量的 M 会激烈竞争这个全局锁,导致严重的性能瓶颈。
- 缺乏局部性:当一个 Goroutine 创建了新的 Goroutine 时,新的 Goroutine 会被放到全局队列的末尾,而不是在创建它的 M 上运行。这破坏了缓存局部性,影响了性能。
- M 阻塞问题:当一个 M 因为系统调用而阻塞时,它上面运行的 Goroutine 也会被阻塞,即使这个 Goroutine 本身并不需要等待系统调用的结果。
5.新的 GMP 模型
对比被废弃的 GM 模型,新出现的 GMP 模型引入一个关键的中间层:P(Processor),下面重新定义这三个核心组件:
- G(Goroutine):代表一个 goroutine,包含了 goroutine 的栈、程序计数器、以及其他执行上下文信息。每个 G 都有自己的栈空间,初始大小为 2KB,可以动态扩展。
- M(Machine):代表一个操作系统线程,是真正执行代码的实体。M 必须绑定一个 P 才能执行 Goroutine。M 的数量通常等于 CPU 核心数,但在某些情况下可能会创建更多。
- P(Processor):这是 GMP 模型的创新所在。P 代表一个逻辑处理器,它维护着一个本地的 Goroutine 队列。P 的数量通常等于
GOMAXPROCS的值,默认为 CPU 核心数。
出现的 GMP 模型如何解决 GM 出现的问题:
- 减少锁竞争:每一个逻辑处理器(P)都有自己的本地队列,线程(M)只需要从绑定的逻辑处理器(P)的本地队列中获取 Goroutine,大大减少了锁竞争
- 提高缓存局部性:相关的 Goroutine 更可能在同一个 P 上运行,提高了缓存命中率
- 减少阻塞:当 线程 因系统调用阻塞时,P 可以绑定到其他 M 继续工作。
6.启动一个 Go 程序的调度过程
- 首先,Go 运行时会创建一个主 Goroutine 来执行 main 函数。这个 Goroutine 被称为 G0,它是整个程序的起点。同时,运行时会根据 GOMAXPROCS 的设置创建相应数量的 P。默认情况下,GOMAXPROCS 等于机器的 CPU 核心数,这意味着你有几个 CPU 核心,就会创建几个 P。
- 接下来,运行时会创建第一个 M(M0),并将其与第一个 P(P0)绑定。这个 M0 开始执行主 Goroutine。其他的 P 初始时处于空闲状态,等待有 Goroutine 需要执行时再创建对应的 M。
类比餐厅:
这个过程就像是在开餐厅的第一天:你先安排了几个服务区域(P),雇佣了第一个服务员(M0)来负责第一个区域(P0),并开始接待第一位客人(主 Goroutine)。其他区域暂时空置,等有更多客人时再安排服务员。
当程序中创建新的 Goroutine 时,这些 Goroutine 会优先放入当前 P 的本地队列。如果有空闲的 P,运行时可能会创建新的 M 来执行这些 Goroutine,从而充分利用多核优势。
7.本地队列满了怎么办?
每个 P 的本地队列都有容量限制,通常为 256 个 Goroutine。
当 P 的本地队列已满时,Go 调度器会采用一种巧妙的策略:它会将本地队列中的一半 Goroutine 移动到全局队列中,然后将新创建的 Goroutine 放入本地队列。
这种设计的好处在于:
- 通过批量移动,避免了频繁地向全局队列添加单个 Goroutine,减少了全局锁的争用
- 保持了本地队列的活跃性
8.本地队列空了怎么办?
当一个 逻辑处理器(P)的本地队列为空时,对应的 线程(M) 并不会闲着,而是会主动寻找工作。
- 首先,M 会检查全局队列是否有 Goroutine。如果有,它会从全局队列中取出一部分 Goroutine 到自己的本地队列中。为了公平性,每次从全局队列取出的 Goroutine 数量是有限制的,通常是 min(len(global_queue)/GOMAXPROCS, 127)。
- 如果全局队列也为空,M 就会开始"工作窃取"。它会随机选择其他的 P,尝试从它们的本地队列中窃取一半的 Goroutine。这个窃取过程是随机的,避免了多个空闲 M 同时瞄准同一个 P 的情况。
- 如果工作窃取也没有成功,M 会检查网络轮询器(netpoller)中是否有就绪的 Goroutine。网络轮询器主要处理网络 I/O 相关的 Goroutine,当网络事件就绪时,相关的 Goroutine 就可以继续执行。
- 如果以上步骤都没有找到可执行的 Goroutine,M 就会进入自旋状态,不断重复上述查找过程。如果自旋一段时间后仍然没有找到工作,M 就会休眠,直到有新的 Goroutine 需要执行时被唤醒。
9.Channel
通道(Channel)是用于 Goroutine 之间的数据传递。
9.1 Channel 语法
使用 make 函数创建一个 channel,使用 <- 操作符发送和接收数据。如果未指定方向,则为双向通道。
ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据
// 并把值赋给 v使用chan关键字声明一个通道:
ch := make(chan int)以下实例通过两个 goroutine 来计算数字之和,在 goroutine 完成计算后,它会计算两个结果的和:
package main
import "fmt"
func sum(s []int, ch chan int) {
sum := 0
for _, v := range s {
sum += v
}
ch <- sum // 把 sum 发送到通道 c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
ch := make(chan int)
go sum(s[:len(s)/2], ch) // 切片操作,取 s 数组的前半部份:3个
go sum(s[len(s)/2:], ch) // 切片操作,取 s 数组的后半部份
x, y := <-ch, <-ch // 从通道 c 中接收
fmt.Println(x, y, x+y)
}执行结果:
-5 17 129.2 无缓冲和有缓冲通道
无缓冲 channel 同步通信。 它们保证每次发送数据时,程序都会被阻止,直到有人从 channel 中读取数据。
相反,有缓冲 channel 将发送和接收操作解耦。 它们不会阻止程序,但你必须小心使用,因为可能最终会导致死锁(如前文所述)。 使用无缓冲 channel 时,可以控制可并发运行的 goroutine 的数量。
10.小结
并发:指一个 CPU 可以同时执行多个任务
Go实现并发基础:Goroutines 、 Channel 、Scheduler
| 定义 | Go 中的并发执行单位,类似于轻量级的线程 | 用于 Goroutine 之间的数据传递 | 调度器会将 Goroutine 分配到系统线程中执行,并通过 系统协程(Machine) 和 P逻辑处理器(Processor)的配合高效管理并发 |
|---|---|---|---|
| Goroutines | Channel | Scheduler | |
| 使用 | 使用 chan 关键字创建,通过 <- 操作符发送和接收数据 | ||
| 优点 | 非阻塞的,可以高效地运行成千上万个 Goroutine;用户无需手动分配线程 | 支持同步和数据共享,避免了显式的锁机制 |