微服务&分布式
1.微服务定义
微服务是一种软件架构风格,将一个大型应用划分为一组小型、自治且松耦合的服务。每个微服务负责执行特定的业务功能,各个微服务可以独立开发、部署和扩展,通过轻量级通信机制相互协作
2.微服务开源方案
目前主流的微服务开源方案有三种:Dubbo、Spring Cloud Netflix、Spring Cloud Alibaba
- Dubbo 是一个高性能、轻量级的Java 微服务框架,最初由阿里巴巴(Alibaba)开发并于2011年开源。它提供了服务注册与发现、负载均衡、容错、分布式调用等功能,后来一度停止维护,在近两年,又重新开始迭代, 并推出了 Dubbo3。Dubbo 使用基于 RPC(Remote Procedure Call)的通信模型,具有较高的性能和可扩展性。它支持多种传输协议(如 TCP、HTTP、Redis)和序列化方式(如 JSON、Hessian、Protobuf),可根据需求进行配置。
- Spring Cloud Netflix 是 Spring Cloud 的一个子项目,结合了 Netflix 开源的多个组件,但是 Netflix 自2018 年停止维护和更新 Netflix OSS 项目,包括 Eureka、Hystrix 等组件,所以 Spring Cloud Netflix 也逐渐进入了维护模式。
- Spring Cloud Alibaba 是 Spring Cloud 的另一个子项目,与阿里巴巴的分布式应用开发框架相关。它提供了一整套与 Alibaba 生态系统集成的解决方案。
3.常见组件
| 描述 | Spring Cloud Netflix | Spring Cloud Alibaba | Restful API | RPC | |
|---|---|---|---|---|---|
| 注册中心 | 用于服务的注册与发现 | Eureka、Consul | Nacos | ||
| 配置中心 | 用于集中管理微服务的配置信息 | Spring Cloud Config | Nacos | ||
| 服务网关 | 微服务架构的入口,统一暴露服务,提供路由、负载均衡 | Zuul | Gateway | ||
| 远程调用 | 用于在不同的微服务之间进行通信协作 | RestTemplate、Feign | Dubbo、grpc | ||
| 服务降级 | 用于防止微服务过载,对请求进行限制和降级处理 | Hystrix | Sentinel | ||
| 服务熔断 | 用于防止微服务之间的故障扩散 | Hystrix | Sentinel | ||
| 分布式追踪和监控 | 用于跟踪和监控微服务的请求流程和性能指标 | Spring Cloud Sleuth + Zipkin | SkyWalking |
4.分布式
4.1 分布式定义
分布式系统是由多台计算机或设备共同工作,通过网络进行通信和协作,以实现一个统一的目标或完成一个共同的任务。分布式系统就是将一个大任务分解成多个小任务,由多台设备共同协作完成,以提高系统的性能和可靠性,这就好像是一个由多个人组成的团队一起完成一项任务一样。
例子
- 组织一个大型派对。如果你自己负责所有准备工作,比如购买食物、装饰场地、发送邀请等,可能会非常辛苦而且效率低下。但如果你将任务分配给一些朋友,比如让其中一人负责食物购买、另一人负责场地布置、再另一人负责发送邀请,那么整个派对的准备工作就会变得更加高效和顺利。这就好像是一个分布式系统,各个部分(人)通过协作完成了一个共同的目标(派对)。
- 在计算机领域,分布式系统也是类似的道理。它将任务分配给多台计算机或设备,每台设备完成一部分工作,然后将结果汇总或交换信息,最终完成整个任务。这种分工合作的方式能够提高系统的性能、可靠性和扩展性,使得系统能够应对更大的负载和更复杂的任务。
优点:
高可用性: 分布式系统通过将数据和计算分布在多个节点上,可以提高系统的可用性。即使某个节点或部分节点发生故障,系统仍然可以继续运行,从而保证了系统的可靠性和持续可用性。
扩展性: 随着业务的增长和用户规模的扩大,单一节点往往无法满足系统的需求。分布式系统可以通过增加节点或者扩展集群规模来实现水平扩展,从而满足系统的性能需求。
容错性: 在分布式系统中,由于存在多个节点,即使部分节点发生故障,系统仍然可以继续运行。通过数据的冗余备份和故障转移等机制,分布式系统能够提高容错性,减少单点故障对系统造成的影响。
地理分布: 分布式系统允许将数据和计算分布在不同地理位置的节点上,从而实现数据的就近访问和处理,提高数据传输的效率和响应速度。
缺点
- 分布式服务依赖网络:服务器间通讯依赖网络,不可靠网络包括网络延时,丢包、中断、异步,一个完整的服务请求依赖一连串服务调用,任意一个服务节点网络出现问题,都可能造成本次请求失败。
- 维护成本高传统单体式服务只需要维护一个站点就可以。分布式服务系统被拆分成若干个小服务,服务从 1 变为几十个上百个服务后,增加运维成本。
- 一致性,可用性,分区容错性无法同时满足:这个是最主要的,这三种特性就是平时说的 CAP 定理,在分布式系统中,这三种特性最多只能满足两种,无法同时满足,需要根据实际情况去调整牺牲掉其中哪个。
4.2 区分分布式和微服务
分布式系统是由多台计算机或设备共同工作,通过网络进行通信和协作,以实现一个统一的目标或完成一个共同的任务的系统。它强调的是系统内部的组织结构和通信方式,以及如何将任务分解并分配给多个计算机或设备来提高系统的性能、可靠性和扩展性。分布式系统可以包括分布式存储系统、分布式计算系统、分布式数据库等。
微服务是一种架构风格,将应用程序构建为一组小型、独立部署的服务,每个服务都围绕着特定的业务功能进行设计和构建,并通过轻量级的通信机制(通常是HTTP API)相互通信。微服务架构的核心理念是将大型单体应用程序拆分为多个小型服务,每个服务都可以独立开发、部署和扩展,从而提高开发速度、灵活性和可维护性。
- 范围不同:
- 分布式系统是一种系统架构模式,强调系统内部的组织结构和通信方式;
- 而微服务是一种架构风格,强调将应用程序构建为一组小型、独立部署的服务。
- 关注点不同:
- 分布式系统关注整个系统的组织和通信方式,以提高系统的性能、可靠性和扩展性;
- 微服务关注的是如何将应用程序拆分为小型、独立部署的服务,以提高开发速度、灵活性和可维护性。
- 实现方式不同:
- 分布式系统可以采用各种架构和技术实现,包括分布式计算、分布式存储、分布式数据库等;
- 微服务通常使用轻量级的通信机制(如HTTP API)来实现服务之间的通信,每个服务可以使用不同的技术栈和编程语言。
举例:
假设你正在建立一个在线电子商务平台:
- 分布式系统: 在这个电子商务平台中,你可能会使用分布式系统来处理不同方面的需求,比如订单管理、用户认证、商品搜索等。分布式系统将这些不同的功能模块分布在多个节点上,以实现高可用性、扩展性和容错性。例如,你可以有一个节点用于订单管理,另一个节点用于用户认证,而另一个节点用于商品搜索。这些节点可以通过网络通信来进行协作和数据交换。
- 微服务架构: 在这个电子商务平台中,你可能会使用微服务架构来组织和管理这些不同的功能模块。每个功能模块都可以作为一个独立的微服务,具有自己的数据存储、业务逻辑和用户界面。例如,你可以有一个订单管理微服务、一个用户认证微服务和一个商品搜索微服务。每个微服务都可以独立部署、扩展和更新,从而实现灵活性和敏捷性。
因此,分布式系统强调的是系统的架构和部署方式,即将系统的不同组件分布在多个节点上,而微服务架构则强调的是系统的设计和组织方式,即将系统拆分成多个小型、独立的服务单元。在实践中,微服务架构通常会使用分布式系统来实现。
4.3 分布式CAP理论和BASE理论
4.3.1 CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这3个基本需求,最多只能同时满足其中的2个
| 选项 | 描述 |
|---|---|
| Consistency(一致性) | 指数据在多个副本之间能够保持一致的特性(严格的一致性) |
| Availability(可用性) | 指系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应(不保证获取的数据为最新数据) |
| Partition tolerance(分区容错性) | 分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障 |
4.3.2 为什么CAP不可兼得
该问题等价于:为什么无法同时保证一致性和可用性?
- 首先对于分布式系统,分区是必然存在的,所谓分区指的是分布式系统可能出现的区域网络不通,成为孤立区域的的情况。
- 那么分区容错性(P)就必须要满足,因为如果要牺牲分区容错性,就得把服务和资源放到一个机器,或者一个“同生共死”的集群,那就违背了分布式的初衷。
那么满足分区容错的基础上,能不能同时满足一致性和可用性?
假设我们优先==保证一致性 (C)==
- 假设有两个节点 N1 和 N2。当我们向 N1 写入数据时,为了确保全局一致性,必须让 N2 的读写操作暂时“冻结”。
- 只有当 N1 完成数据同步至 N2 后,N2 才能恢复处理读写请求。在此期间,客户端针对 N2 的请求要么会收到失败响应,要么会因等待超时而得不到及时反馈。
- 这意味着,在追求强一致性的过程中,N2 的可用性不可避免地受到了影响,因为它无法始终如一地对所有请求提供即时响应。
再来看看优先==保证可用性 (A)==
这次,我们不让 N2 的读写操作暂停。即使 N1 正在进行数据写入,N2 也继续处理客户端的请求。但这样一来,N2 可能会基于过时数据作出响应,导致客户端接收到与全局最新状态不一致的结果。
显然,这种情况下,虽然我们保证了 N2 的高可用性(即对所有请求都有响应),却牺牲了数据的一致性。💫 Confused 😵
综上所述,在分布式系统的设计中,由于分区容错性的必然存在,我们无法同时确保一致性和可用性达到理想状态。二者就像是天平的两端,提升一方就意味着另一方的妥协。要根据实际业务需求和容忍度来决定在 CAP 三要素中如何取舍
4.3.3 CAP对应的模型及应用
| CP | AP | |
|---|---|---|
| 描述 | 放弃A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。 | 要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。 |
| 常见应用 | 分布式数据库、分布式锁、Zookeeper | Web缓存、DNS、Eureka |
4.3.4 BASE理论
BASE(Basically Available、Soft state、Eventual consistency)是基于CAP理论逐步演化而来的
核心思想是即便不能达到强一致性(Strong consistency),也可以根据应用特点采用适当的方式来达到最终一致性(Eventual consistency)的效果。
主要含义:
- Basically Available(基本可用)
什么是基本可用呢?假设系统出现了不可预知的故障,但还是能用,只是相比较正常的系统而言,可能会有响应时间上的损失,或者功能上的降级。
- Soft State(软状态)
什么是硬状态呢?要求多个节点的数据副本都是一致的,这是一种“硬状态”。
软状态也称为弱状态,相比较硬状态而言,允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
- Eventually Consistent(最终一致性)
上面说了软状态,但是不应该一直都是软状态。在一定时间后,应该到达一个最终的状态,保证所有副本保持数据一致性,从而达到数据的最终一致性。这个时间取决于网络延时、系统负载、数据复制方案设计等等因素。
5.分布式锁
5.1 定义
分布式锁是一种用于在分布式系统中实现互斥访问的机制。
它允许多个进程或线程在不同的节点上同步访问共享资源,确保在任何时刻只有一个进程或线程可以持有锁,并且能够安全地释放锁,以避免资源竞争和数据不一致的问题。
5.2 实现分布式锁方案
常见的分布式锁实现方案有三种:MySQL分布式锁、ZooKepper分布式锁、Redis分布式锁。
5.2.1 MySQL
用数据库实现分布式锁比较简单,就是创建一张锁表,数据库对字段作唯一性约束。
加锁的时候,在锁表中增加一条记录即可;释放锁的时候删除记录就行。
如果有并发请求同时提交到数据库,数据库会保证只有一个请求能够得到锁。
这种属于数据库 IO 操作,效率不高,而且频繁操作会增大数据库的开销,因此这种方式在高并发、高性能的场景中用的不多。
5.2.2 Redis
Redis实现分布式锁,是当前应用最广泛的分布式锁实现方式。
Redis执行命令是单线程的,Redis实现分布式锁就是利用这个特性。
实现分布式锁最简单的一个命令:setNx(set if not exist),如果不存在则更新:
setNx resourceName value加锁了之后如果机器宕机,那我这个锁就无法释放,所以需要加入过期时间,而且过期时间需要和setNx同一个原子操作,在Redis2.8之前需要用lua脚本,但是redis2.8之后redis支持nx和ex操作是同一原子操作。
set resourceName value ex 5 nx5.2.3 ZooKeeper分布式锁
ZooKeeper也是常见分布式锁实现方法。
ZooKeeper的数据节点和文件目录类似,例如有一个lock节点,在此节点下建立子节点是可以保证先后顺序的,即便是两个进程同时申请新建节点,也会按照先后顺序建立两个节点。
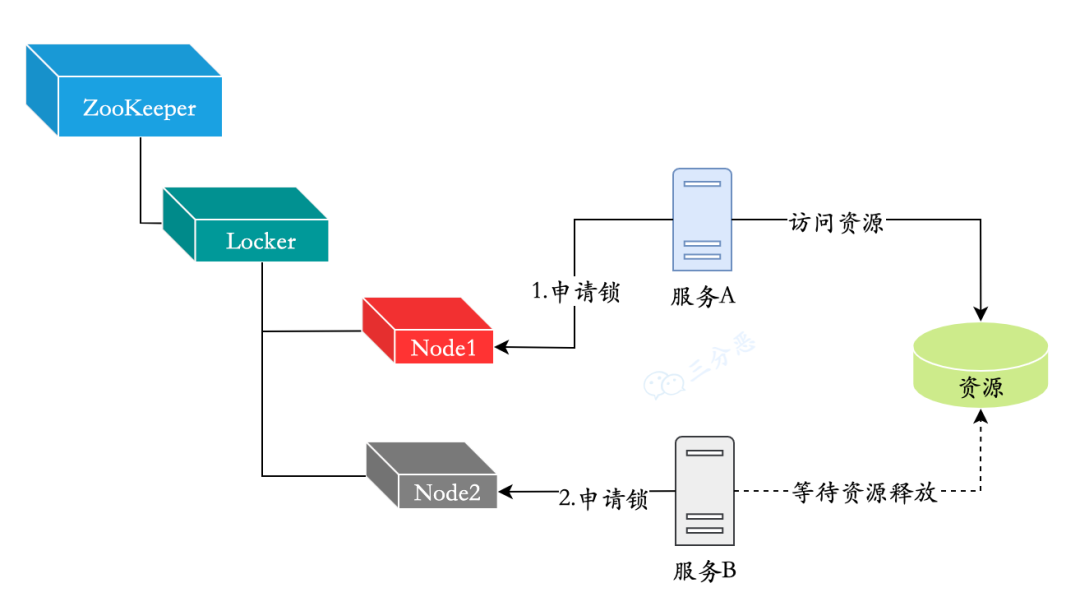
所以我们可以用此特性实现分布式锁。以某个资源为目录,然后这个目录下面的节点就是我们需要获取锁的客户端,每个服务在目录下创建节点,如果它的节点,序号在目录下最小,那么就获取到锁,否则等待。释放锁,就是删除服务创建的节点。
ZK实际上是一个比较重的分布式组件,实际上应用没那么多了,所以用ZK实现分布式锁,其实相对也比较少。
6.幂等性设计
6.1 什么是幂等性
- 幂等性是一个数学概念,用在接口上:用在接口上就可以理解为:同一个接口,多次发出同一个请求,请求的结果是一致的。
- 简单说,就是多次调用如一次。
6.2 什么是幂等性问题
在系统的运行中,可能会出现这样的问题:
- 用户在填写某些
form表单时,保存按钮不小心快速点了两次,表中竟然产生了两条重复的数据,只是id不一样。 - 开发人员在项目中为了解决
接口超时问题,通常会引入了重试机制。第一次请求接口超时了,请求方没能及时获取返回结果(此时有可能已经成功了),于是会对该请求重试几次,这样也会产生重复的数据。 - mq消费者在读取消息时,有时候会读取到
重复消息,也会产生重复的数据。
6.3 怎么保证接口幂等性
一共有7种方法保证接口幂等性:
- insert前先select(中等推荐)
- 加唯一索引(推荐)
- 加悲观锁(不推荐)
- 加乐观锁(推荐)
- 建防重表
- 状态机
- token机制(推荐)
6.3.1 insert前先select
在保存数据的接口中,在insert前,先根据非主键等字段先select一下数据。如果该数据已存在,则直接返回,如果不存在,才执行 insert操作。
6.3.2 加唯一索引
- 加唯一索引是个非常简单但很有效的办法,如果重复插入数据的话,就会抛出异常,为了保证幂等性,一般需要捕获这个异常。
- 如果是
java程序需要捕获:DuplicateKeyException异常,如果使用了spring框架还需要捕获:MySQLIntegrityConstraintViolationException异常。
6.3.3 加悲观锁
更新逻辑,比如更新用户账户余额,可以加悲观锁,把对应用户的哪一行数据锁住。同一时刻只允许一个请求获得锁,其他请求则等待。
select * from user id=123 for update;这种方式有一个缺点,获取不到锁的请求一般只能报失败,比较难保证接口返回相同值。
6.3.4 加乐观锁
更新逻辑,也可以用乐观锁,性能更好。可以在表中增加一个
timestamp或者version字段,例如version:在更新前,先查询一下数据,将version也作为更新的条件,同时也更新version:
update user set amount=amount+100,version=version+1 where id=123 and version=1;更新成功后,version增加,重复更新请求进来就无法更新了。
6.3.5 建防重表
有时候表中并非所有的场景都不允许产生重复的数据,只有某些特定场景才不允许。这时候,就可以使用防重表的方式。
例如消息消费中,创建防重表,存储消息的唯一ID,消费时先去查询是否已经消费,已经消费直接返回成功。
6.3.6 状态机
有些业务表是有状态的,比如订单表中有:1-下单、2-已支付、3-完成、4-撤销等状态,可以通过限制状态的流动来完成幂等。
6.3.7 token机制
- 请求接口之前,需要先获取一个唯一的token
- 再带着这个token去完成业务操作,服务端根据这个token是否存在,来判断是否是重复的请求。
7.限流算法
7.1 计算器
- 计数器比较简单粗暴,比如我们要限制1s能够通过的请求数
- 实现的思路就是从第一个请求进来开始计时,在接下来的1s内,每个请求进来请求数就+1,超过最大请求数的请求会被拒绝,等到1s结束后计数清零,重新开始计数。
这种方式有个很大的弊端:比如前10ms已经通过了最大的请求数,那么后面的990ms的请求只能拒绝,这种现象叫做“突刺现象”。
7.2 漏桶算法
原理:
桶底出水的速度恒定,进水的速度可能快慢不一
但是当进水量大于出水量的时候,水会被装在桶里,不会直接被丢弃;但是桶也是有容量限制的,当桶装满水后溢出的部分还是会被丢弃的。
核心思想: 接收指定数量的请求,按照指定的速率处理。
算法实现:
- 可以准备一个队列来保存暂时处理不了的请求,然后通过一个线程池定期从队列中获取请求来执行。
缺点:并发性差,需要对每个水滴(请求)逐个进行处理
7.3 令牌桶限流
核心思想:
- 令牌桶就是生产访问令牌的一个地方,生产的速度恒定
- 用户访问的时候当桶中有令牌时就可以访问,否则将触发限流。
算法步骤:
- 每隔一段时间生成一定数量的令牌放入桶中;
- 当有请求到达时,从桶中获取一个令牌,如果没有令牌可用,则拒绝该请求。
实现方案:Guava RateLimiter限流
Guava RateLimiter是一个谷歌提供的限流,其基于令牌桶算法,比较适用于单实例的系统。
优点:令牌桶限流的并发性能比较高,我们可以批量对拿到令牌的请求进行处理。