Redis底层数据结构
1.前言
2.跳表
Redis的基本数据类型Zset的底层实现就用到了跳表,跳表的平均复杂度为O(logN)
Zset结构体里面维护了两个数据结构:
- 跳表,支持高效的范围查询
- 哈希表:支持高效的单点查询
2.1 跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N)
于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,可以快速定位数据
跳表的粗略样子如下:
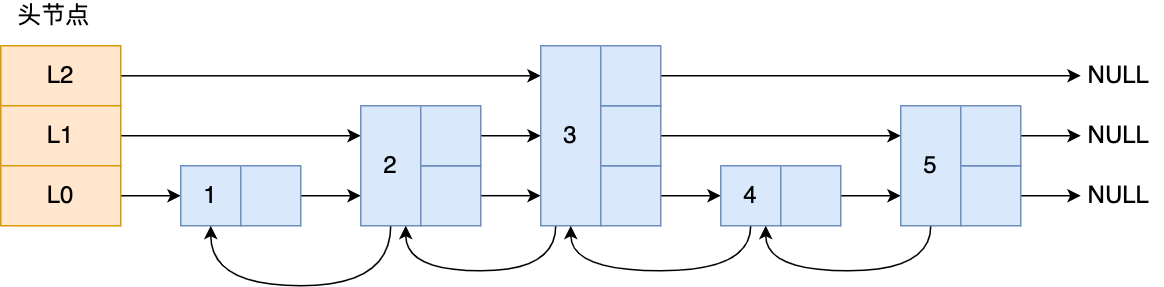
图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
- L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
- L1 层级共有 3 个节点,分别是节点 2、3、5;
- L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次;
而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
引出一个问题:跳表节点是如何实现多层级的?看看Redis设计跳表节点的数据结构:
typedef struct zskiplistNode {
// Zset 对象的元素值
sds ele;
// 元素权重值
double score;
// 后退指针
struct zskiplistNode *backward;
// 节点的level数组,保存每层上的前进指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;如上所示,每一个zset元素都保存了【元素】、【元素的权重】、【后退指针】、【层级数组】
- 元素:使用sds数据类型
- 元素权重:使用double类型
- 后向指针:指向了前一个节点,目的是为了方便从跳表的尾节点开始访问节点,高效支持倒序查找
- 层级数组:数组的每一个元素,都保存了元素的前进指针(指向下一个节点)和跨度
什么是跨度?
跨度,实际上代表了这个节点在跳表中的排位
问题:如何计算某个节点的跨度?
从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
各个节点的跨度如下图所示

问题:上图展示了 zskiplistNode跳表节点,但是哪个跳表节点是头节点,我们并不能看出来,所以下面引出【跳表】结构体
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;跳表 zskiplist 结构体有:
- 跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
- 跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
- 跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
2.2 跳表节点查询过程
查找一个跳表节点的过程时,首先,跳表会从头节点的最高层开始,遍历每一层。
在遍历某一层的跳表节点时,会用跳表节点的 SDS 类型的元素值 和 元素权重 来进行判断,共有两个判断条件:
- 如果当前节点的权重【小于】要查找的权重时,跳表就会访问该层的下一个节点。
- 如果当前节点的权重【等于】要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举例,如图为三层级的跳表

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束
2.3 跳表小结
- 跳表是在基于链表基础建立的,是一种多层的有序链表,时间复杂度为O(logN)
- 每个跳表节点都包含了节点元素、元素权重、后退指针、以及层级数组(实现链表的多层),其中层级数组包含了在每一层中节点的前进指针、以及跨度(对下一个节点)。跨度代表了节点在跳表中的排位
- 查找跳表中节点时,从第一层开始访问,根据【节点元素权重】和【SDS类型的元素】进行比较,慢慢的跳到下一层1
- zset什么选用跳表当作数据结构,不选用平衡树?
- 支持高效的范围查询:
- 平衡树:找到指定范围的小值之后,还需要以中序遍历继续寻找不超过大值的节点
- 跳表:只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现
- 内存占用小:
- 平衡树每个节点包含 2 个指针(分别指向左右子树),
- 而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势
- 支持高效的范围查询: