ES文章检索
1.前言
在本篇中,我们将使用ElasticSearch实现文章检索,使用Canal实现ES和MySQL数据同步,其中具体实现了全量数据同步和增量数据同步;同时将整合ES客户端实现数据检索
2.环境准备
我们需要安装ElasticSearch(v7.17.4)、Kinaba(v7.17.4)、IK分词器(v7.17.4)、Canal(v1.1.7)
一定一定要保持下载版本和上述的一致,不然会出现各种版本不兼容问题,启动失败
2.1 ElasticSearch
docker安装ES命令:
# 拉取ES镜像
docker pull elasticsearch:7.17.4# 启动ES容器 注意/mydata/elasticsearch/plugins,后面会用到
docker run --name my-es -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.17.4- 测试是否创建成功:ip地址:9200
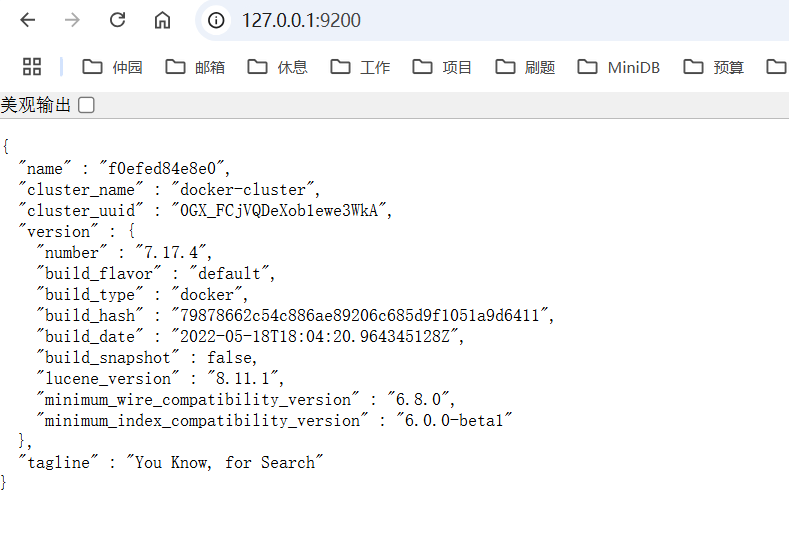
2.2 Kibana
docker安装kibana命令:
docker pull kibana:7.17.4# 注意,若ES安装在本地,则ES的地址要填虚拟地址(ipconfig命令)
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.234.128:9200 -p 5601:5601 \
-d kibana:7.17.4- 测试是否访问成功:http://127.0.0.1:5601/
- 操作ES地址:http://localhost:5601/app/dev_tools#/console
2.3 IK分词器
- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.17.4
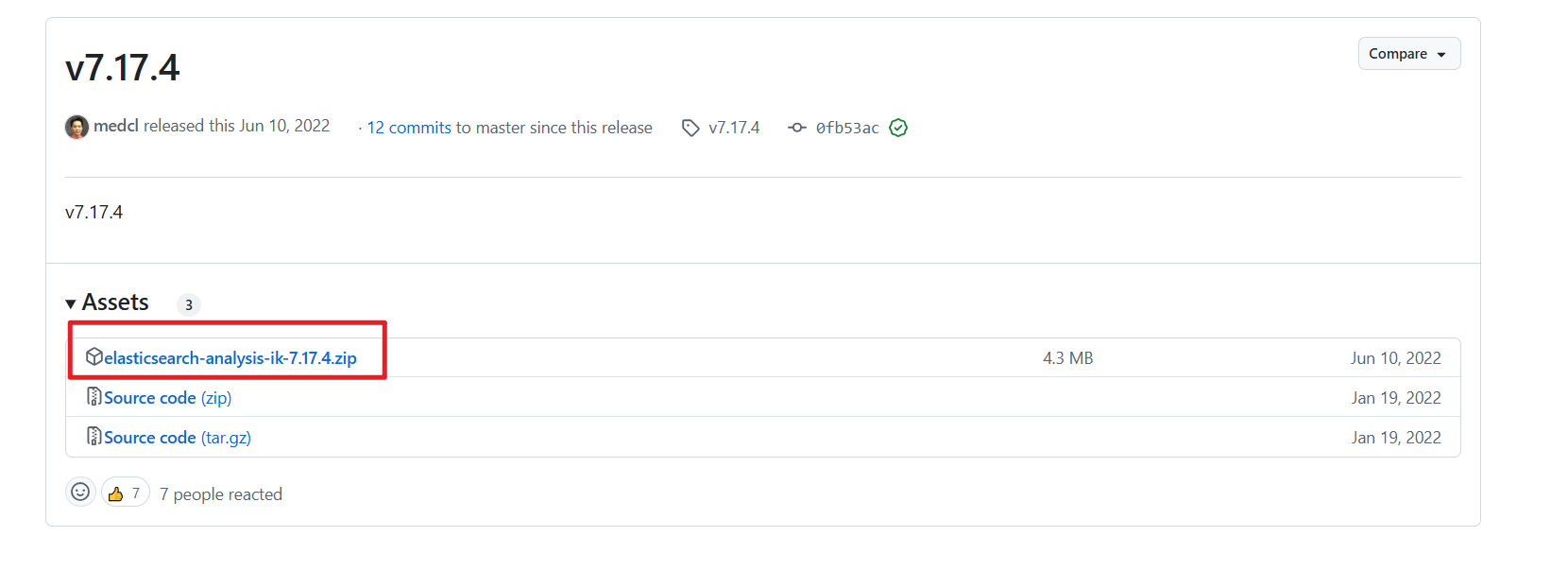
- 将下载的压缩包解压缩在ES的plugins文件夹下,并重命名为ik。虚拟机即/mydata/elasticsearch/plugins位置,windows见自己设置的映射位置:
- 重启ES,测试是否安装成功
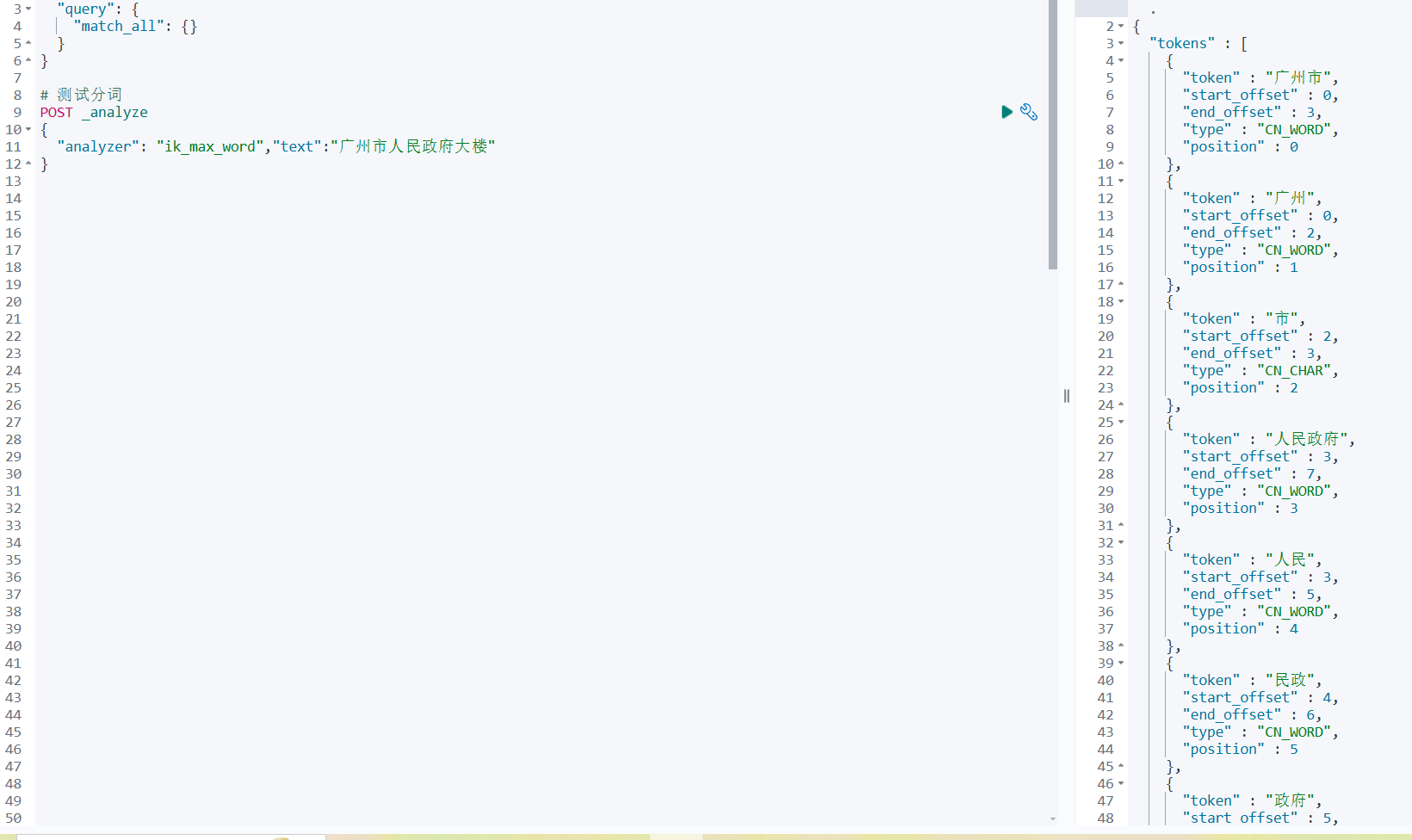
2.4 Canal
2.4.1 下载地址
- 下载地址:https://github.com/alibaba/canal/releases/tag/canal-1.1.7
- 注意:必须下载v1.1.7正式版本,都是本人亲自踩的坑😭😭😭
- 1.1.6正式版本兼容不了 JDK1.8版本,需要升级 JDK版本
- 1.1.7的alpha版本会出现 配置不能以"_"开头导致的esMaping反序列化失败 的bug
- canal.deployer:canal的服务端,可以在客户端接收数据库变更信息
- canal.adapter:增加客户端数据落地的适配,即当服务端接收到消息后,会根据不同的目标源做适配,比如ES目标源和hbase适配
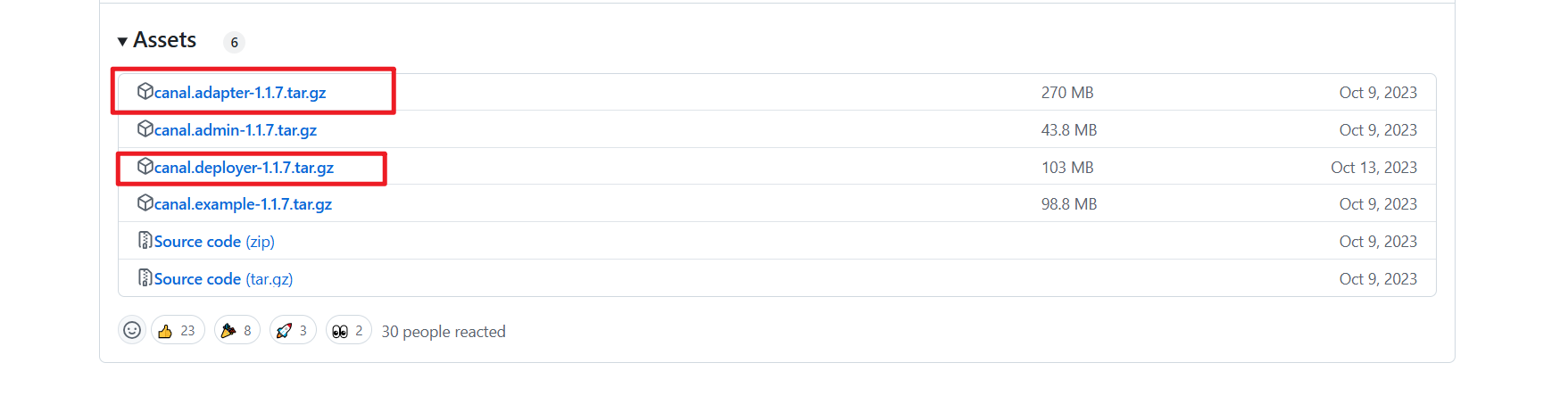
2.4.2 canal.deployer配置
- 修改:conf文件夹的canal.properties,服务端注册的地址、端口;用于adapter发现
# register ip to zookeeper
canal.register.ip = 127.0.0.1
canal.port = 11111- 修改:conf——>example文件夹的 instance.properties 监听的数据库配置
# position info
canal.instance.master.address=127.0.0.1:3306- 启动:bin文件夹的startup.bat命令
- 查看日志:

2.4.3 canal.adapter配置
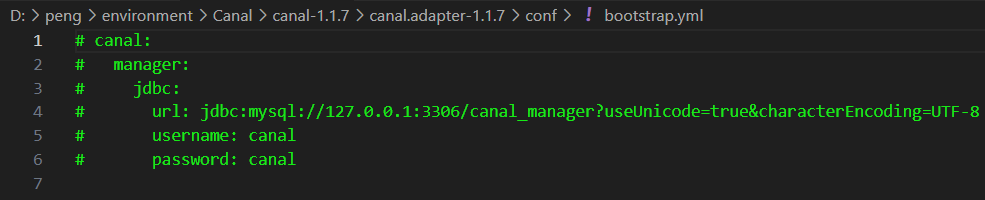
- 首先,把adapter 的config 下面的 bootstrap.yml 内容全部注释掉,否则会提示 XX 表不存在
- 修改:adapter 的config 的 application.yml 配置文件,连接canal的服务端、全量数据同步设置、ES配置
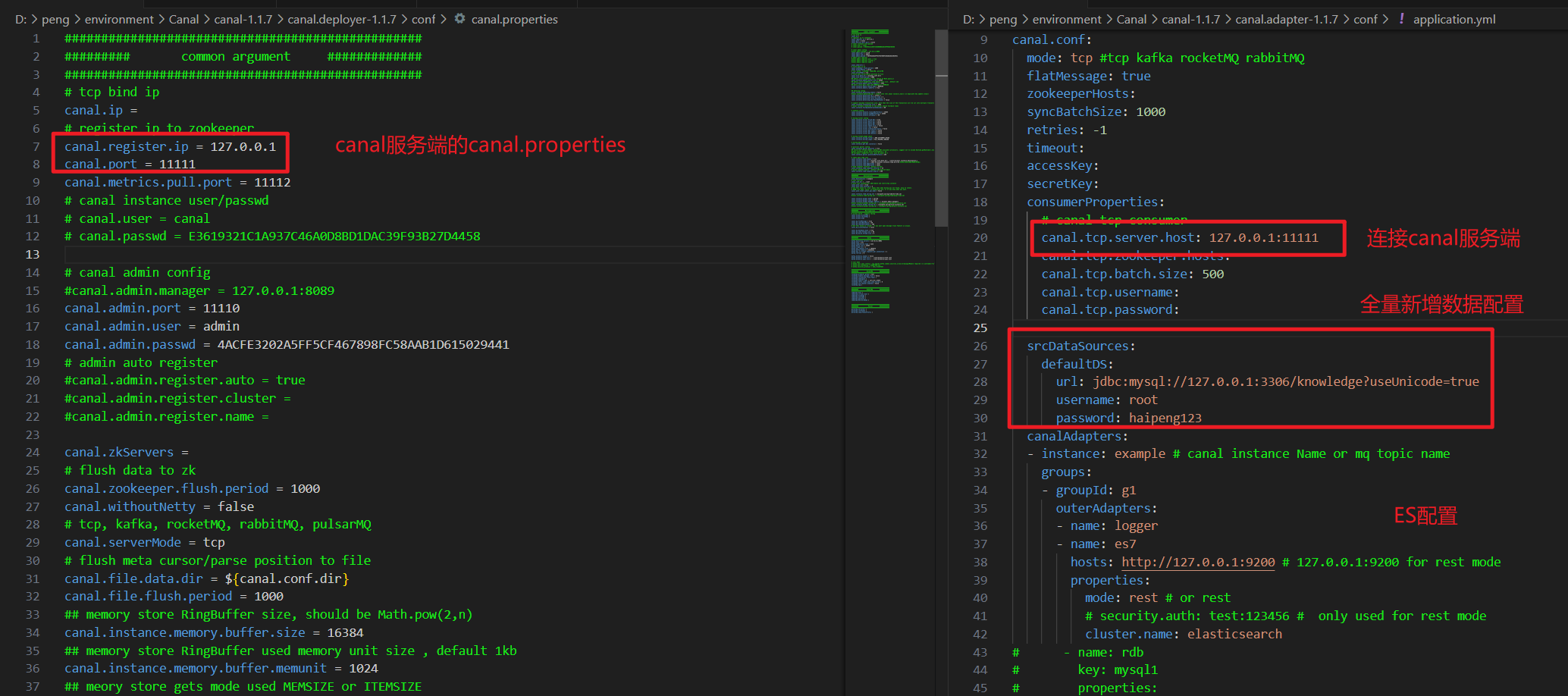
- 新增:在adapter——>config——>es文件夹新增文件 article.yml,对article表进行监听
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: article
_id: _id
# upsert: true
# pk: id
sql: "SELECT t.id As _id, t.id, t.user_id, t.article_type,t.title,t.short_title,t.picture,t.summary,t.category_id,t.source,t.source_url,t.offical_stat,t.topping_stat,
t.cream_stat,t.status,t.deleted,t.create_time,t.update_time
FROM article t"
#sq1映射
commitBatch: 1- 启动:bin目录下的startup.bat命令,启动8081端口
2.5 ES新增索引
PUT /article
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"user_id": {
"type": "integer"
},
"article_type": {
"type": "integer"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"short_title": {
"type": "text",
"analyzer": "ik_max_word"
},
"picture": {
"type": "text",
"analyzer": "ik_max_word"
},
"summary": {
"type": "text",
"analyzer": "ik_max_word"
},
"category_id": {
"type": "integer"
},
"source": {
"type": "integer"
},
"source_url": {
"type": "text",
"analyzer": "ik_max_word"
},
"offical_stat": {
"type": "integer"
},
"topping_stat": {
"type": "integer"
},
"cream_stat": {
"type": "integer"
},
"status": {
"type": "integer"
},
"deleted": {
"type": "integer"
},
"create_time": {
"type": "date"
},
"update_time": {
"type": "date"
}
}
}
}2.6 数据同步
2.6.1 全量同步
- 使用adapter服务提供的接口实现全量数据同步
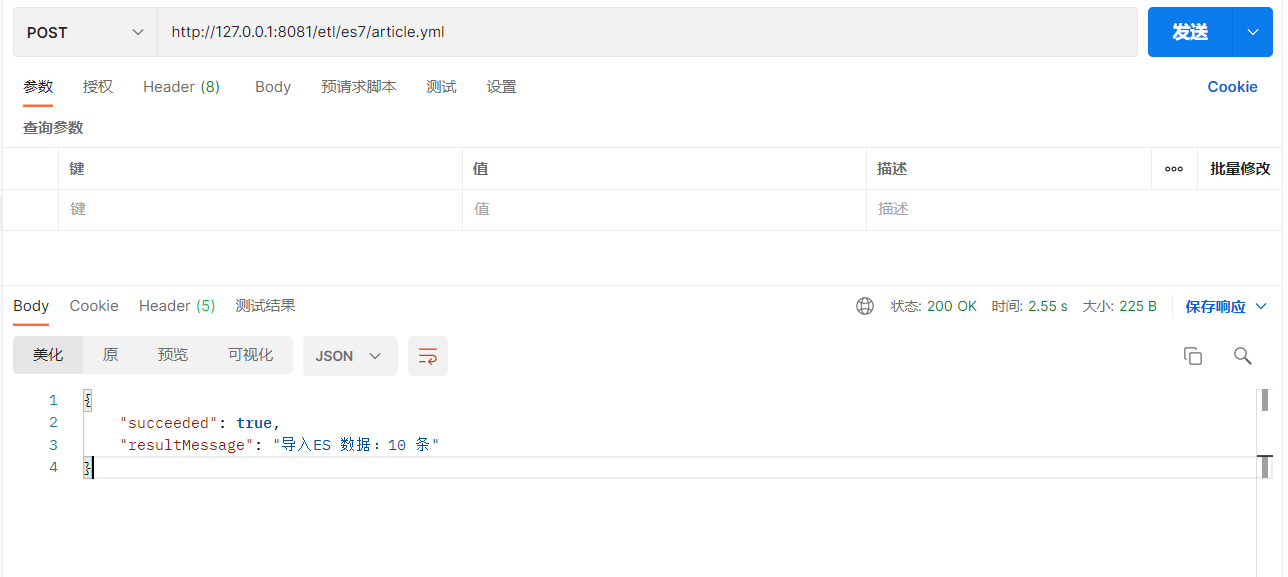
- 查询数据:
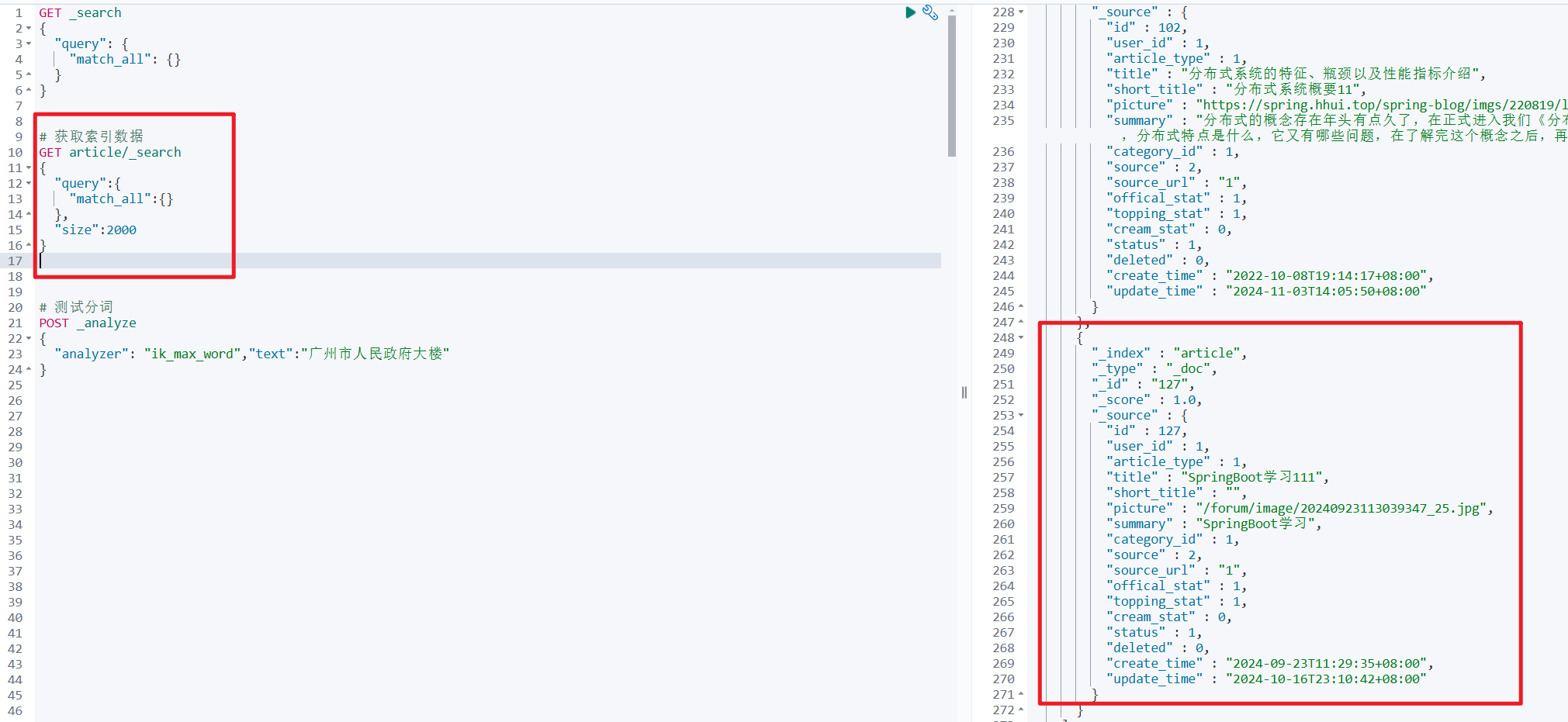
2.6.2 增量同步
- 新增、修改、删除文章都会同时修改ES的数据

3.ES客户端检索数据
3.1 引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.8.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>6.8.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.8.2</version>
</dependency>3.2 配置yml
# elasticsearch配置
elasticsearch:
# 是否开启ES?本地启动如果没有安装ES,可以设置为false关闭ES
open: false
# es集群名称
clusterName: elasticsearch
hosts: 127.0.0.1:9200
userName: elastic
password: elastic
# es 请求方式
scheme: http
# es 连接超时时间
connectTimeOut: 1000
# es socket 连接超时时间
socketTimeOut: 30000
# es 请求超时时间
connectionRequestTimeOut: 500
# es 最大连接数
maxConnectNum: 100
# es 每个路由的最大连接数
maxConnectNumPerRoute: 1003.3 ES配置类
@Slf4j
@Data
@Configuration
// 下面这个表示只有 elasticsearch.open = true 时,采进行es的配置初始化;当不使用es时,则不会实例 RestHighLevelClient
@ConditionalOnProperty(prefix = "elasticsearch", name = "open")
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticsearchConfig {
// 是否开启ES
private Boolean open;
// es host ip 地址(集群)
private String hosts;
// es用户名
private String userName;
// es密码
private String password;
// es 请求方式
private String scheme;
// es集群名称
private String clusterName;
// es 连接超时时间
private int connectTimeOut;
// es socket 连接超时时间
private int socketTimeOut;
// es 请求超时时间
private int connectionRequestTimeOut;
// es 最大连接数
private int maxConnectNum;
// es 每个路由的最大连接数
private int maxConnectNumPerRoute;
/**
* 如果@Bean没有指定bean的名称,那么这个bean的名称就是方法名
*/
@Bean(name = "restHighLevelClient")
public RestHighLevelClient restHighLevelClient() {
// 此处为单节点es
String host = hosts.split(":")[0];
String port = hosts.split(":")[1];
HttpHost httpHost = new HttpHost(host, Integer.parseInt(port));
// 构建连接对象
RestClientBuilder builder = RestClient.builder(httpHost);
// 设置用户名、密码
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));
// 连接延时配置
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(connectTimeOut);
requestConfigBuilder.setSocketTimeout(socketTimeOut);
requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeOut);
return requestConfigBuilder;
});
// 连接数配置
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(maxConnectNum);
httpClientBuilder.setMaxConnPerRoute(maxConnectNumPerRoute);
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
return httpClientBuilder;
});
return new RestHighLevelClient(builder);
}
}3.4 ES检索数据
@Override
public List<SimpleArticleDTO> querySimpleArticleBySearchKey(String key) {
// 当key为空时,返回热门推荐
if (StringUtils.isBlank(key)) {
return Collections.emptyList();
}
key = key();
if (!openES) {
// 1、数据库检索
List<ArticleDO> records = articleDao.listSimpleArticlesByBySearchKey(key);
return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle()))
.collect(Collectors.toList());
}
// 2、ES检索
// 2.1、SearchSourceBuilder:构建搜索请求
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 2.2、MultiMatchQueryBuilder:构建多字段匹配查询
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(key,
EsFieldConstant.ES_FIELD_TITLE,
EsFieldConstant.ES_FIELD_SHORT_TITLE);
searchSourceBuilder.query(multiMatchQueryBuilder);
// 2.3、执行查询
SearchRequest searchRequest = new SearchRequest(new String[]{EsIndexConstant.ES_INDEX_ARTICLE}, searchSourceBuilder);
SearchResponse searchResponse = null;
try {
searchResponse = SpringUtil.getBean(RestHighLevelClient.class).search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("failed to query from es: key", e);
}
// 2.4、获取查询结果的命中(SearchHits),并提取所有命中的文章(SearchHit数组)。
// 创建一个ids列表,收集所有匹配文章的ID
SearchHits hits = searchResponse.getHits();
SearchHit[] hitsList = hits.getHits();
List<Integer> ids = new ArrayList<>();
for (SearchHit documentFields : hitsList) {
ids.add(Integer.parseInt(documentFields.getId()));
}
if (ObjectUtils.isEmpty(ids)) {
return null;
}
List<ArticleDO> records = articleDao.selectByIds(ids);
return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle()))
.collect(Collectors.toList());
}
``` -->