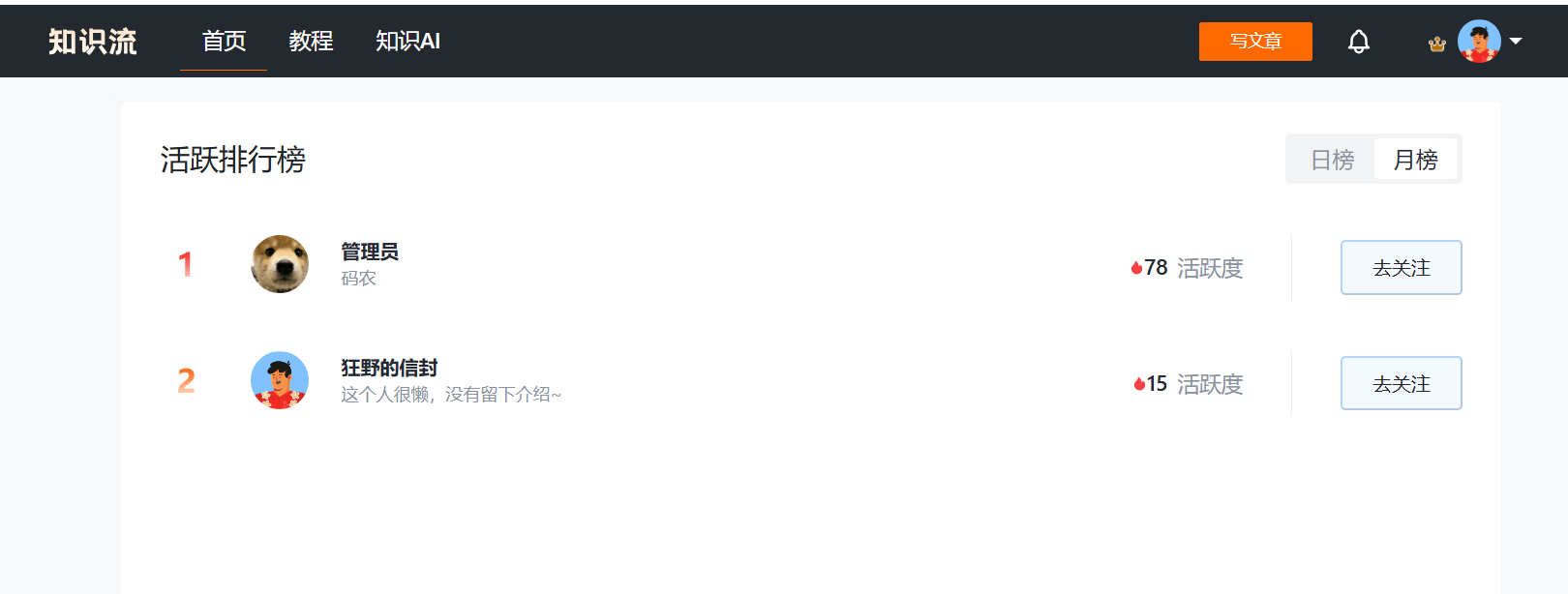
用户活跃排行榜
1.前言
作为一个知识交流社区,为让平台用户有参与感,我们使用 Redis 的 zset 数据结构实现了用户月、日活跃排行榜
- 效果图:
2.方案设计
2.1 活跃度计算方式
- 用户每访问一个页面:+1分
- 对于一篇文章,点赞、收藏:+2分,取消则收回活跃分
- 发布一篇审核通过的文章:+10分
同时,只展示月、日活跃度最高的前30名用户
2.2 存储单元
存储单元可看作是后端返回给前端的数据
// 用户标识
long userId;
// 用户在排行榜上的排名
long rank;
// 用户的积分
long score;2.3 zset数据结构
我们使用了Redis的zset数据结构,实现了月/日排行榜
- set:确保集合元素的唯一性
- score:每个元素的积分
- 排名:根据积分获取排名
3.项目实战
3.1 封装类
- 排行榜信息类
@Data
@Accessors(chain = true)
public class RankItemDTO {
/**
* 排名
*/
private Integer rank;
/**
* 评分
*/
private Integer score;
/**
* 用户
*/
private SimpleUserInfoDTO user;
}- 活跃分业务类
@Data
@Accessors(chain = true)
public class ActivityScoreBo {
/**
* 访问页面增加活跃度
*/
private String path;
/**
* 目标文章
*/
private Long articleId;
/**
* 评论增加活跃度
*/
private Boolean rate;
/**
* 点赞增加活跃度
*/
private Boolean praise;
/**
* 收藏增加活跃度
*/
private Boolean collect;
/**
* 发布文章增加活跃度
*/
private Boolean publishArticle;
/**
* 被关注的用户
*/
private Long followedUserId;
/**
* 关注增加活跃度
*/
private Boolean follow;
}- Zset数据结构
- key:rank_年月日,或者 rank年月
- value:hash结构,key为用户id,value为用户得分
3.2 更新用户活跃分
在实际场景中,由于网络抖动等原因,可能会出现重复发送点赞、收藏等请求,这时会出现加重复的活跃分的情况,所以我们需要做一个幂等,防止重复添加,即判断下之前有没有重复添加过相关的活跃度
3.2.1 幂等策略
我们将用户的每个加分项都直接记录下来,在执行加分操作时,用来做幂等判断
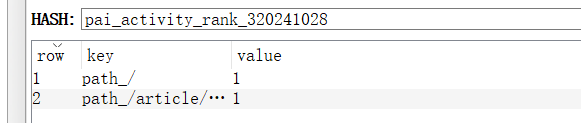
- set数据结构
- key:rank_用户id-年月日
- filed为用户的具体工作(浏览、点赞、评论),值为相应的得分
3.2.2 更新活跃分
基本流程如下:
- 计算此次操作的活跃分,点赞、收藏则为正活跃分,取消则为负数
- 幂等:判断之前是否有更新过相关的活跃度信息。根据 rank_用户id年月日 作为key,动作为field 判断
- 没有加过分:记录加分操作、更新用户月、日活跃榜(使用zset的zincrby命令:zincrby key increment field)
- 加过分:移除用户的活跃执行记录、更新用户月、日活跃榜
@Override
public void addActivityScore(Long userId, ActivityScoreBo activityScore) {
if (userId == null) {
return;
}
// 1. 计算活跃度(正为加活跃,负为减活跃)
String field;
int score = 0;
if (activityScore.getPath() != null) {
field = "path_" + activityScore.getPath();
score = 1;
} else if (activityScore.getArticleId() != null) {
field = activityScore.getArticleId() + "_";
if (activityScore.getPraise() != null) {
field += "praise";
score = BooleanUtils.isTrue(activityScore.getPraise()) ? 2 : -2;
} else if (activityScore.getCollect() != null) {
field += "collect";
score = BooleanUtils.isTrue(activityScore.getCollect()) ? 2 : -2;
} else if (activityScore.getRate() != null) {
// 评论回复
field += "rate";
score = BooleanUtils.isTrue(activityScore.getRate()) ? 3 : -3;
} else if (BooleanUtils.isTrue(activityScore.getPublishArticle())) {
// 发布文章
field += "publish";
score += 10;
}
} else if (activityScore.getFollowedUserId() != null) {
field = activityScore.getFollowedUserId() + "_follow";
score = BooleanUtils.isTrue(activityScore.getFollow()) ? 2 : -2;
} else {
return;
}
final String todayRankKey = todayRankKey();
final String monthRankKey = monthRankKey();
// 2. 幂等:判断之前是否有更新过相关的活跃度信息
final String userActionKey = ACTIVITY_SCORE_KEY + userId + DateUtil.format(DateTimeFormatter.ofPattern("yyyyMMdd"), System.currentTimeMillis());
Integer ans = RedisClient.hGet(userActionKey, field, Integer.class);
if (ans == null) {
// 2.1 之前没有加分记录,执行具体的加分
if (score > 0) {
// 记录加分记录
RedisClient.hSet(userActionKey, field, score);
// 个人用户的操作记录,保存一个月的有效期,方便用户查询自己最近31天的活跃情况
RedisClient.expire(userActionKey, 31 * DateUtil.ONE_DAY_SECONDS);
// 更新当天和当月的活跃度排行榜
Double newAns = RedisClient.zIncrBy(todayRankKey, String.valueOf(userId), score);
RedisClient.zIncrBy(monthRankKey, String.valueOf(userId), score);
if (log.isDebugEnabled()) {
log.info("活跃度更新加分! key#field = {}#{}, add = {}, newScore = {}", todayRankKey, userId, score, newAns);
}
if (newAns <= score) {
// 由于上面只实现了日/月活跃度的增加,但是没有设置对应的有效期;为了避免持久保存导致redis占用较高;因此这里设定了缓存的有效期
// 日活跃榜单,保存31天;月活跃榜单,保存1年
// 为什么是 newAns <= score 才设置有效期呢?
// 因为 newAns 是用户当天的活跃度,如果发现和需要增加的活跃度 scopre 相等,则表明是今天的首次添加记录,此时设置有效期就比较符合预期了
// 但是请注意,下面的实现有两个缺陷:
// 1. 对于月的有效期,就变成了本月,每天的首次增加活跃度时,都会重新刷一下它的有效期,这样就和预期中的首次添加缓存时,设置有效期不符
// 2. 若先增加活跃度1,再减少活跃度1,然后再加活跃度1,同样会导致重新算了有效期
// 严谨一些的写法,应该是 先判断 key 的 ttl, 对于没有设置的才进行设置有效期,如下
Long ttl = RedisClient.ttl(todayRankKey);
if (!NumUtil.upZero(ttl)) {
RedisClient.expire(todayRankKey, 31 * DateUtil.ONE_DAY_SECONDS);
}
ttl = RedisClient.ttl(monthRankKey);
if (!NumUtil.upZero(ttl)) {
RedisClient.expire(monthRankKey, 12 * DateUtil.ONE_MONTH_SECONDS);
}
}
}
} else if (ans > 0) {
// 2.2 之前已经加过分,因此这次减分可以执行
if (score < 0) {
// 移除用户的活跃执行记录 --> 即移除用来做防重复添加活跃度的幂等键
Boolean oldHave = RedisClient.hDel(userActionKey, field);
if (BooleanUtils.isTrue(oldHave)) {
Double newAns = RedisClient.zIncrBy(todayRankKey, String.valueOf(userId), score);
RedisClient.zIncrBy(monthRankKey, String.valueOf(userId), score);
if (log.isDebugEnabled()) {
log.info("活跃度更新减分! key#field = {}#{}, add = {}, newScore = {}", todayRankKey, userId, score, newAns);
}
}
}
}
}3.2.3 触发活跃度更新
我们借助监听器,监听用户的操作事件,并更新对应的活跃度
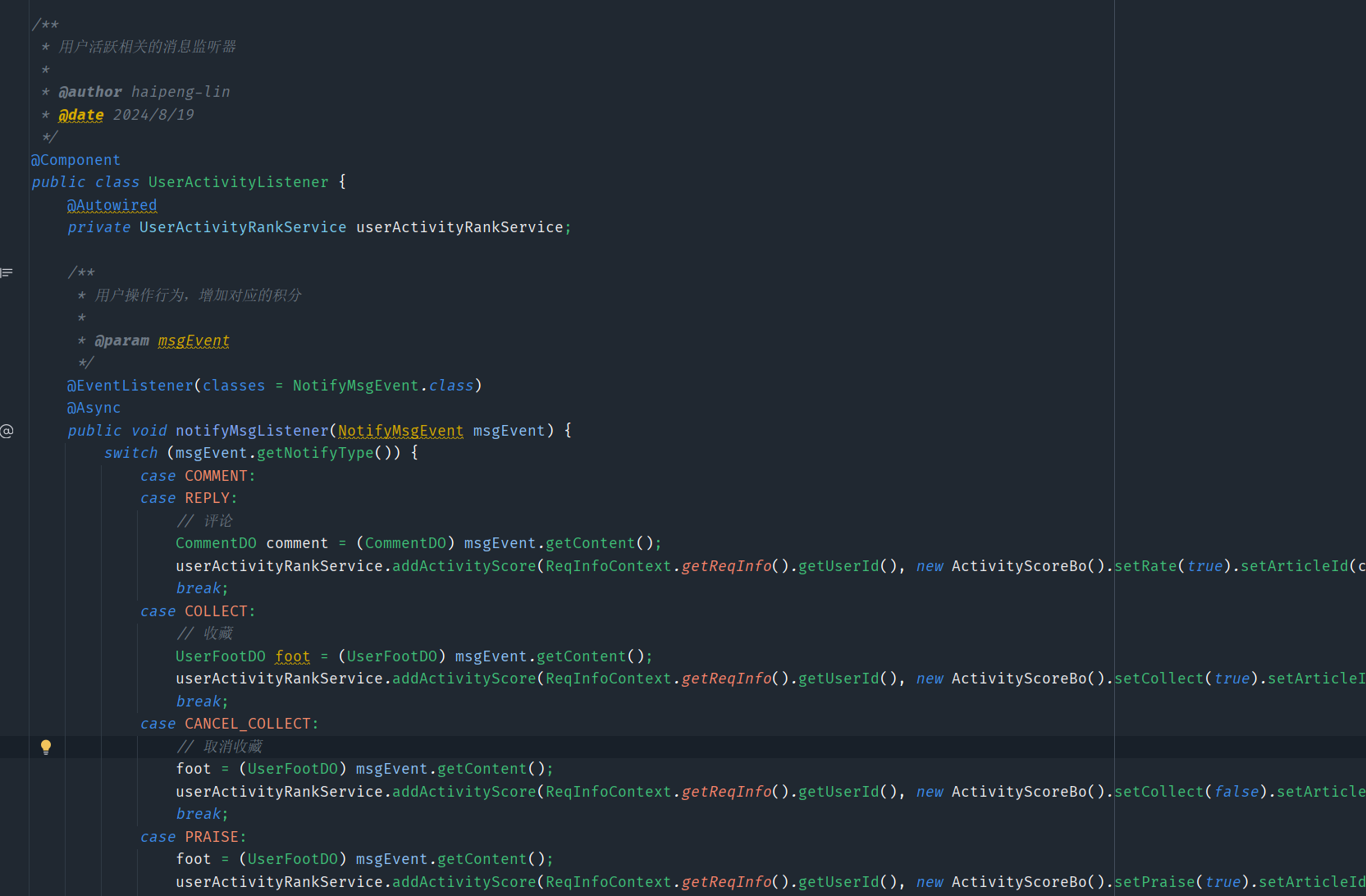
- 用户访问页面
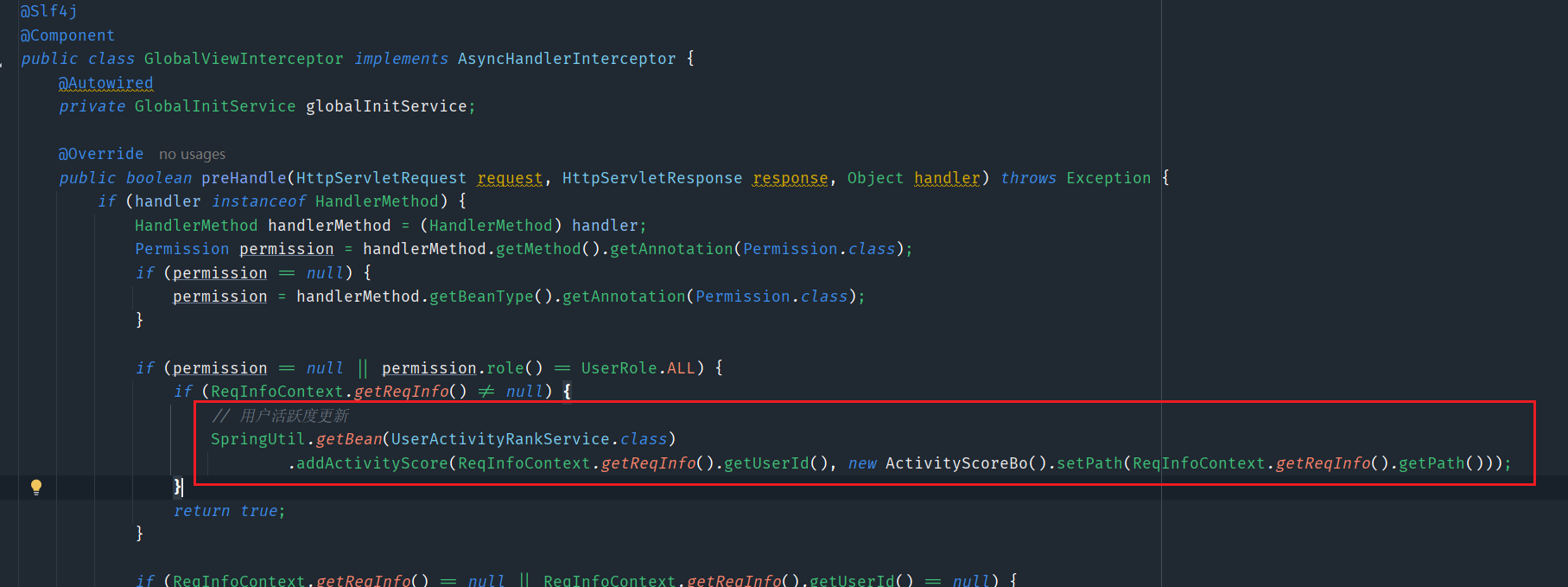
3.3 查询用户排行榜
基本流程如下:
- 从redis中获取TopN的用户+评分
- 查询用户信息
- 根据用户评分进行排序,返回给前端
核心的redis实现
- **原生查询命令:**zrange key start end withscores命令(下标从start到end)如:获取前二十的景点排行榜(zrange key -20 -1 withscores)表示从倒数第二十个元素到倒数第一个元素
- redisClient命令:
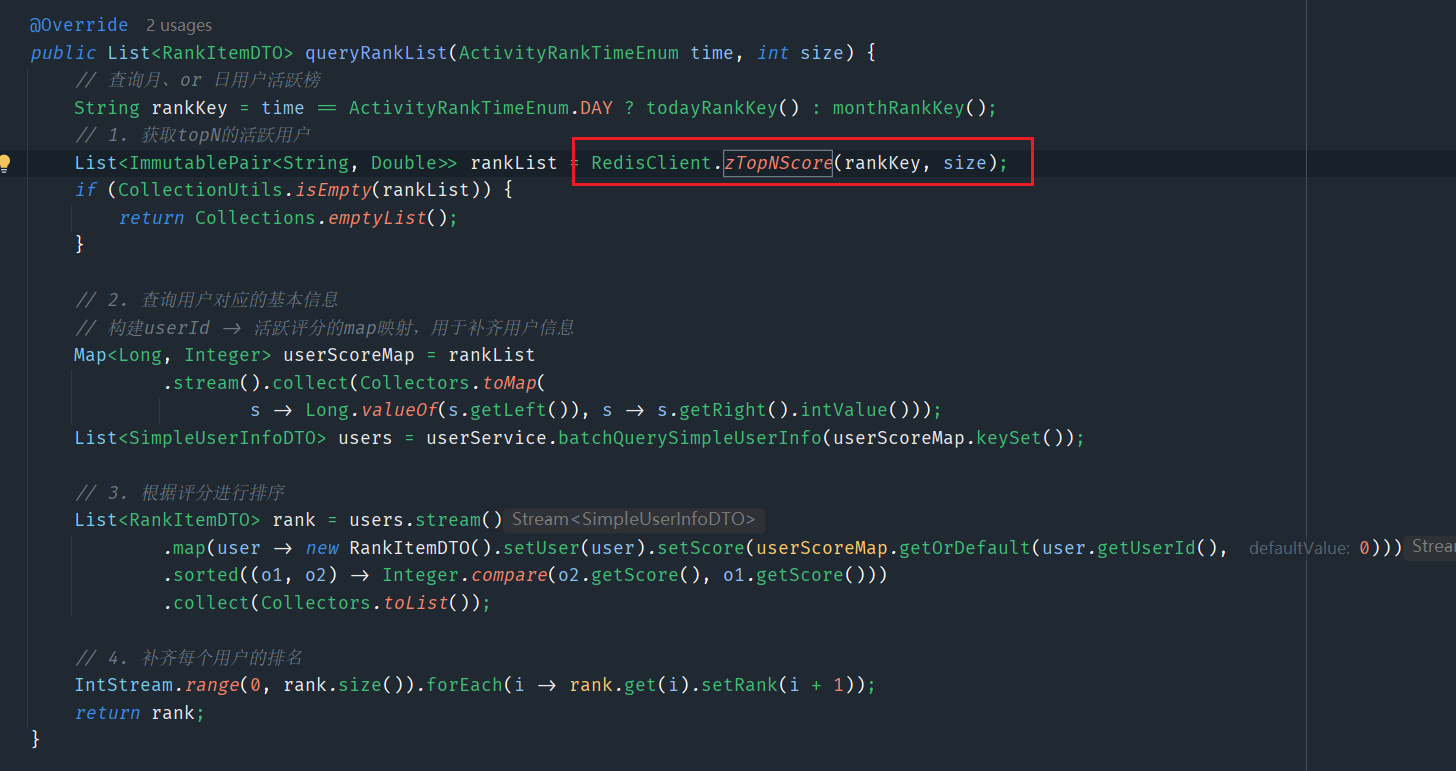
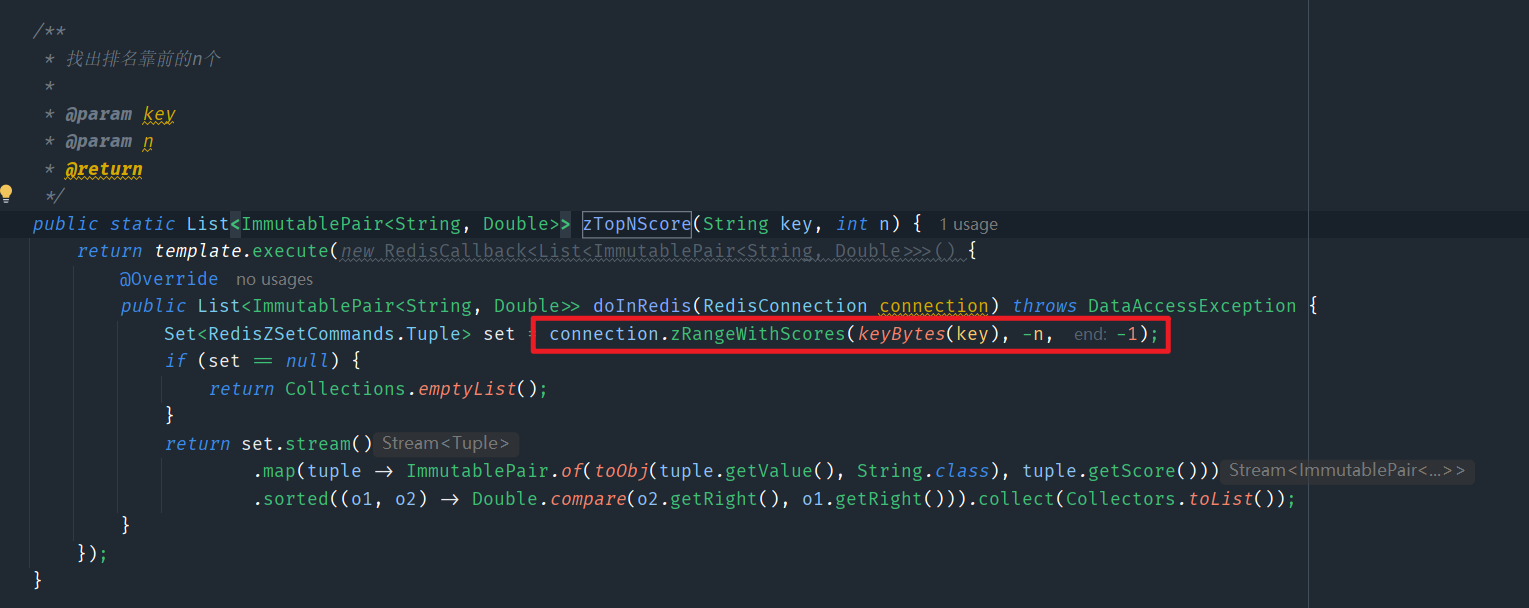
4.Zset底层数据结构
在 Redis 中,ZSET(有序集合)是一种非常强大的数据结构,它结合了集合和有序列表的特性。ZSET 的底层实现主要依赖于一种数据结构:跳跃表(Skip List)
4.1 何为跳跃表
跳跃表是一种概率性数据结构,它允许在平均 O(log N) 时间复杂度内完成查找、插入和删除操作。跳跃表由**多个层(level)**组成,每一层都是一个有序链表,最底层(level 1)包含所有的元素,而上层的链表是下层链表的子集。通过这种方式,跳跃表可以在 O(log N) 时间内完成查找操作。
跳跃表的主要优点是它实现简单,并且插入和删除操作的时间复杂度较低。此外,跳跃表还支持范围查询,这在某些应用场景中非常有用。
4.2 插入数据
如图为redis插入数据的过程:
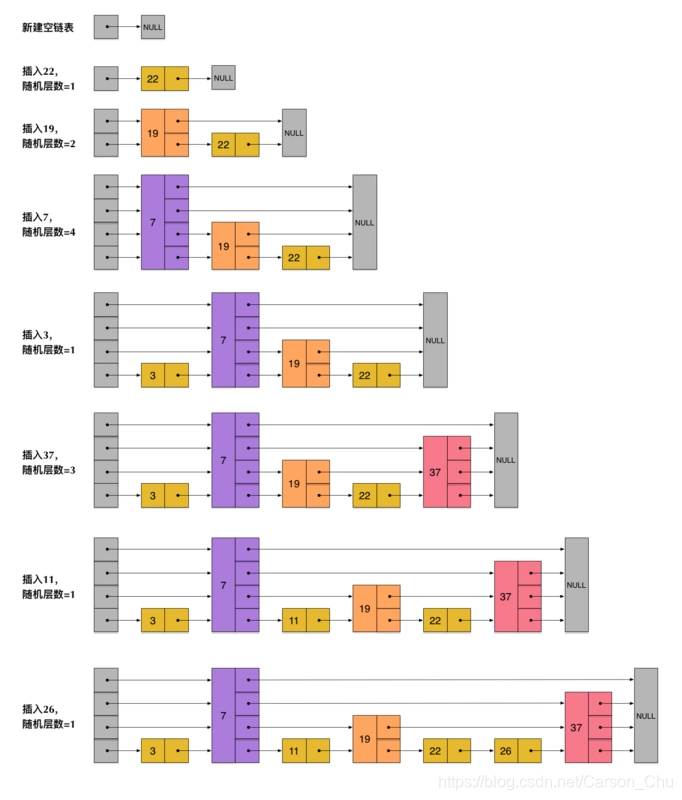
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
4.3 为什么采用跳表,不使用哈希标或平衡树实现
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。